Why is Apache Spark is faster than MapReduce?
Why is Apache Spark getting all the attention when it comes to the Big Data space? Why is Apache Spark 100x faster than MapReduce and how is it possible is the question for many in this space. This blog post is my way to answer this question.
Why is Apache Spark getting attention in Big Data Space?
Well, the answer is, for the scenarios where parallel processing is required and have many interdependent tasks, Apache Spark in memory processing offers the best big data processing platform. Hence the attention.
Why is Apache Spark faster than MapReduce?
Data processing requires computer resource like the memory, storage, etc. In Apache Spark, the data needed is loaded into the memory as Resilient Distributed Dataset (RDD) and processed in parallel by performing various transformation and action on it. In some cases, the output RDD from one task is used as input to another task, creating a lineage of RDDs which are inter-dependent on each other. However, in traditional MapReduce, here is an overhead for reading and writing data on disk after each sub task task.
Here is the architectural diagram for Spark:
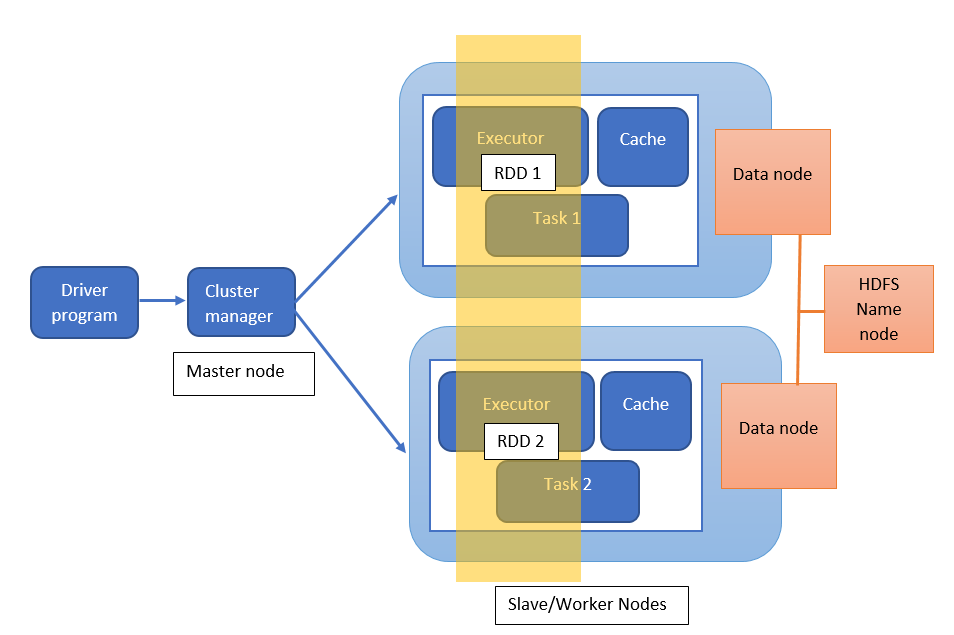
Why is apache spark faster than MapReduce
Hence Apache Spark is always faster than traditional Map Reduce.
Thanks for dropping by !!! Feel free to comment to this post or you can reply back to me at naik899@gmail.com
The post Why is Apache Spark faster than MapReduce? appeared first on RavindraNaik.


Comments
Post a Comment